The Eternal Sunshine of the Toil-less Prod
A presentation at QConSF in in San Francisco, CA, USA by Sasha Czarkowski (Rosenbaum)

Toil Toil is the kind of work that tends to be manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows. 1

@DivineOps SRE teams usually aim for under 50% toil

@DivineOps If an employee is told that 50% of their work has no enduring value, how does this affect their productivity and job satisfaction? - Byron Miller

The eternal sunshine of the toil-less prod Sasha Rosenbaum @DivineOps

Dev B.Sc. in C.S. Ops MBA Dev + Ops Cloud Consulting DevRel Technical Sales Sasha Rosenbaum @DivineOps
@DivineOps And you?

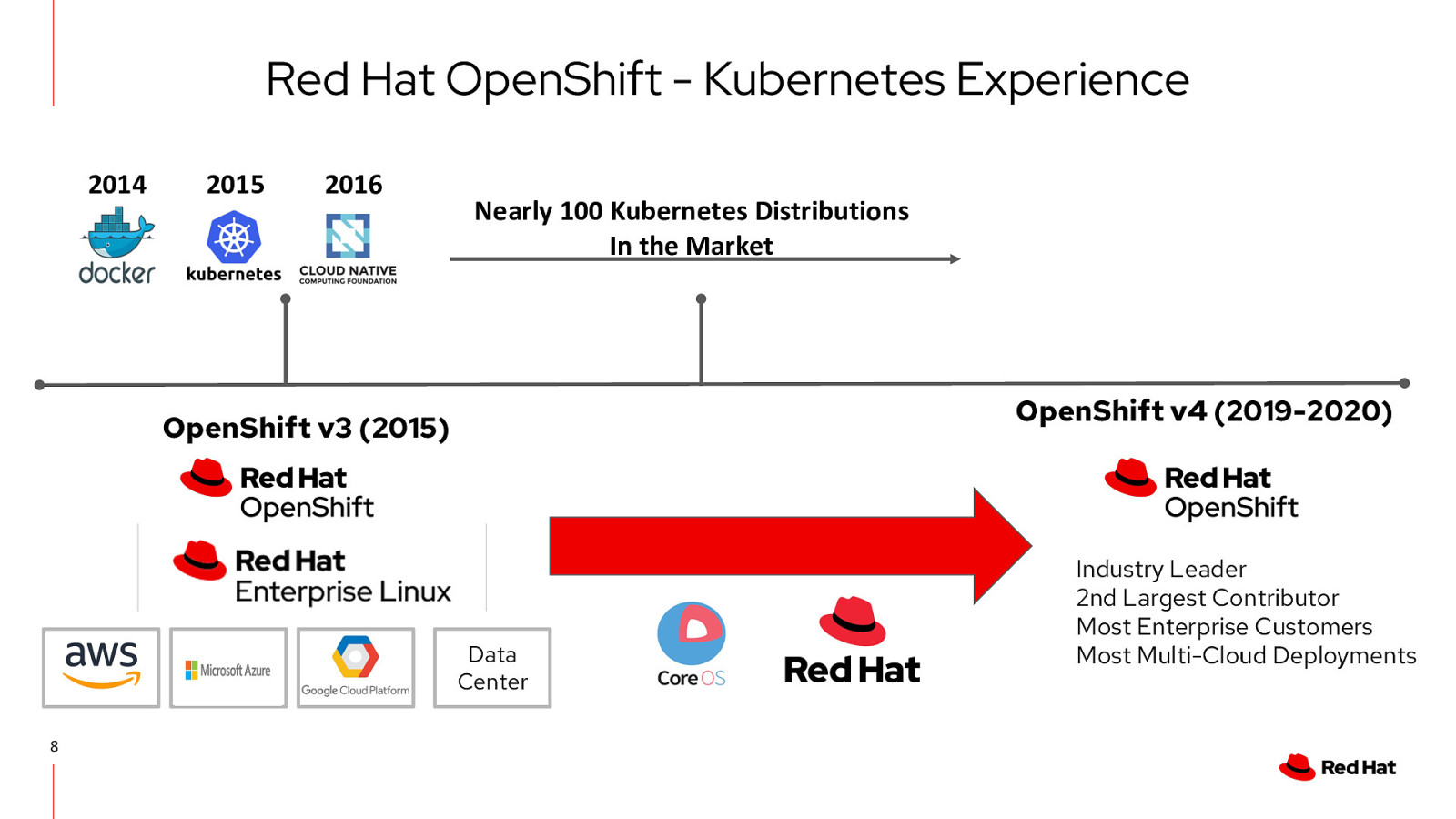
Red Hat OpenShift - Kubernetes Experience 2014 2015 2016 Nearly 100 Kubernetes Distributions In the Market OpenShift v4 (2019-2020) OpenShift v3 (2015) Data Center 8 Industry Leader 2nd Largest Contributor Most Enterprise Customers Most Multi-Cloud Deployments
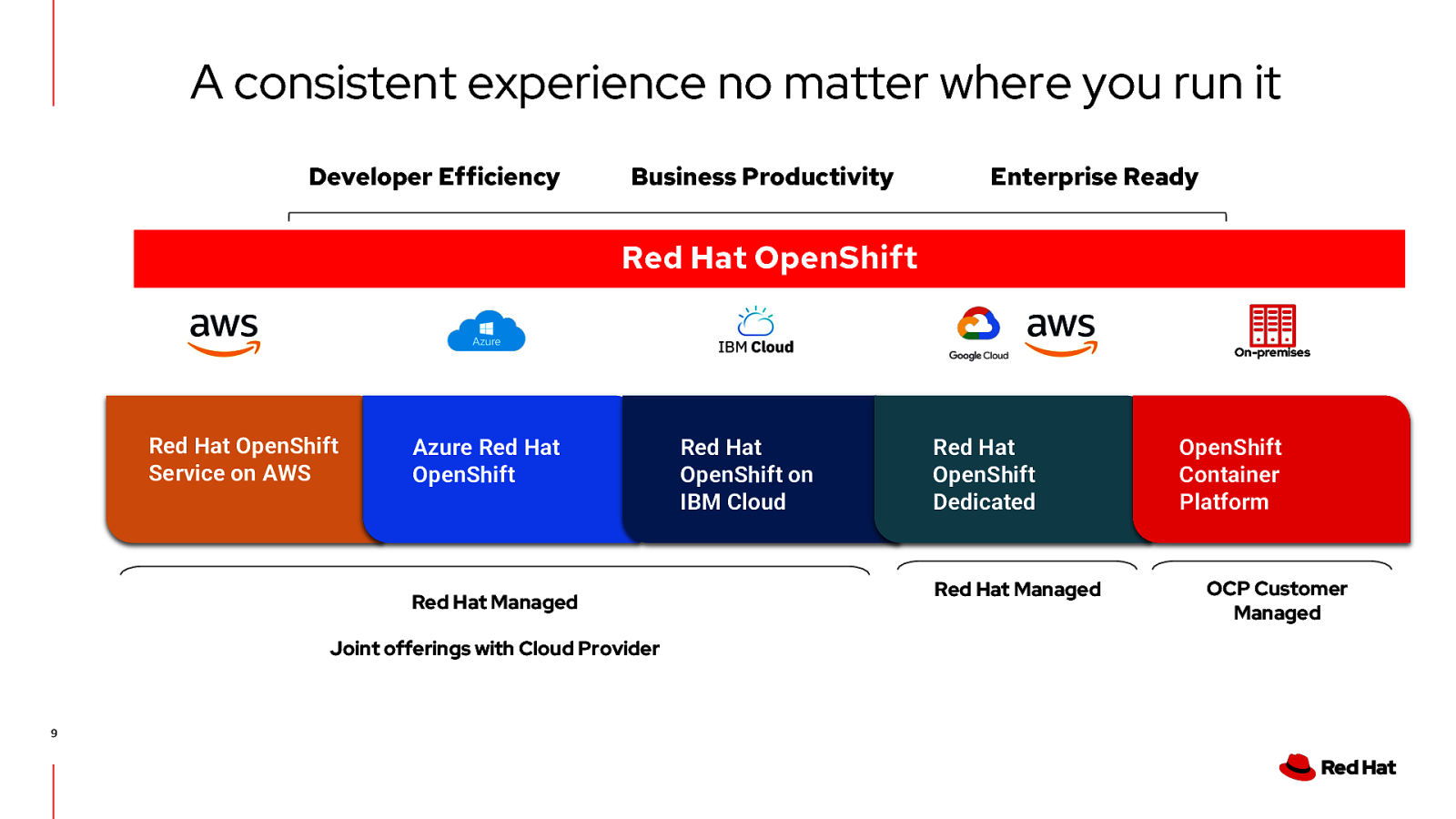
A consistent experience no matter where you run it Developer Efficiency Business Productivity Enterprise Ready Red Hat OpenShift On-premises Red Hat OpenShift Service on AWS Azure Red Hat OpenShift Red Hat Managed Joint offerings with Cloud Provider 9 Red Hat OpenShift on IBM Cloud Red Hat OpenShift Dedicated Red Hat Managed OpenShift Container Platform OCP Customer Managed
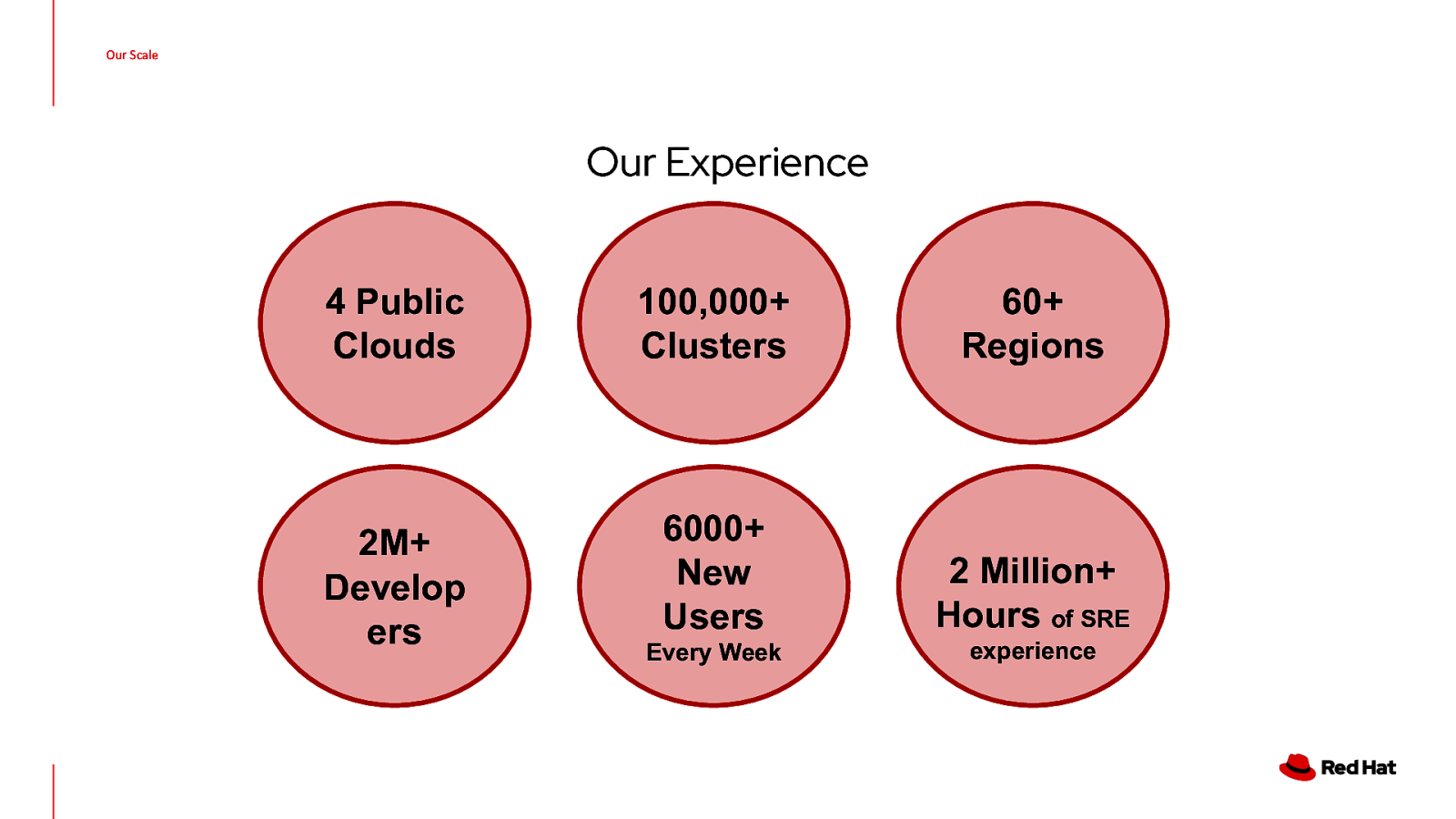
Our Scale Our Experience 4 Public Clouds 100,000+ Clusters 60+ Regions 2M+ Develop ers 6000+ New Users 2 Million+ Hours of SRE Every Week experience

@DivineOps Products to Services

@DivineOps Products and Services

@DivineOps SRE

@DivineOps What is the most important and innovative thing about SRE discipline?

@DivineOps SRE is about explicit agreements that align incentives

@DivineOps SLA, SLI, SLO

@DivineOps SLA = Financially-backed availability

@DivineOps Monthly downtime > 1.5 days means 100% refund

@DivineOps SLAs are about aligning incentives between Vendor & Customer

@DivineOps 99% => 99.99%

@DivineOps • SLA usually includes a single metric • For financial and reputational reasons, companies prefer to under promise and overdeliver

@DivineOps SLO = Targeted reliability
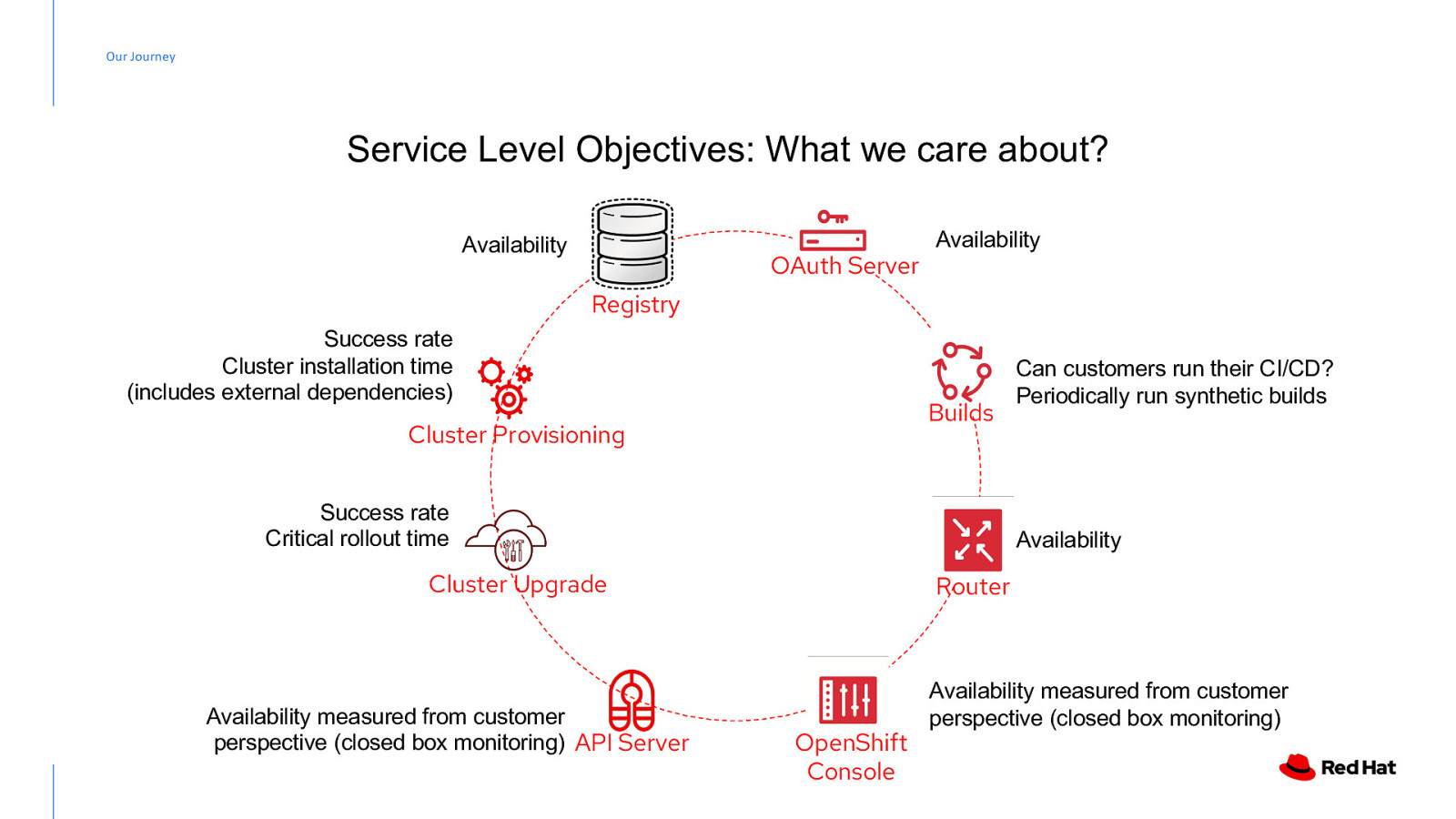
Our Journey Service Level Objectives: What we care about? Availability OAuth Server Availability Registry Success rate Cluster installation time (includes external dependencies) Builds Cluster Provisioning Success rate Critical rollout time Availability Cluster Upgrade Availability measured from customer perspective (closed box monitoring) API Server Can customers run their CI/CD? Periodically run synthetic builds Router OpenShift Console Availability measured from customer perspective (closed box monitoring)

@DivineOps SLI = Actual reliability

@DivineOps Monitoring

@DivineOps Without monitoring, you have no way to tell whether your service even works!

@DivineOps Good Monitoring

@DivineOps Without good monitoring, you don’t know that the service does what users expect it to do!

@DivineOps Signal to noise ratio

@DivineOps Early on, one of the major monitoring problems we had is alerts on customer clusters that were intentionally taken offline

@DivineOps Without good monitoring, your SRE is potentially overloaded with unwarranted emergencies and blindsided by real incidents

@DivineOps Periodically incidents may be caught by internal users, rather than the monitoring system We aim to implement monitoring improvements that will catch future problems of the same kind

@DivineOps SLO

@DivineOps SLO = Business-approved reliability

100% reliability is… •Unattainable •Unnecessary •Extremely expensive

The five nines 99.999% 5.26 mins / year

@DivineOps Will your users even notice?

@DivineOps The ISP background error rate is 0.01% - 1%

@DivineOps SLOs are about explicitly aligning incentives between Business & Engineering

Error Budgets Acceptable level of unreliability Error budget = 1 - SLO EB = 1 – 99.99% = 0.01% ≃ 13 mins /quarter

@DivineOps Error budgets are about aligning incentives between Dev & Ops

@DivineOps If developers are measured on the same SLO, then when the error budget is drained developers shift focus from delivering new features to improving reliability

@DivineOps So, we’ve written things down

@DivineOps Are we there yet?

The future is already here. It’s just not evenly distributed ~ William Gibson

@DivineOps Awkward Segue

@DivineOps What we all got wrong

@DivineOps

@DivineOps “SRE is what happens when you ask a software engineer to design an operations team.” - Google SRE book, 2017

@DivineOps Is it though?

@DivineOps DevOps

DevOpsDays Ghent 2009

@DivineOps Automate ourselves out of a job!

@DivineOps So why didn’t we do it?

@DivineOps Effective automation requires consistent APIs

@DivineOps OS-level APIs

2000 27% of server market 41% of server market • File-based OS • Maintains configuration in files • Every device is a file • Executable-based OS • Maintains configuration in registry • Every device has a different driver mechanism

@DivineOps PowerShell (Windows) configuration management framework, CLI, and scripting language GA: 2006 Jeffrey Snover

@DivineOps DevOpsDays Seattle 2019: Thriving Through Transitions by Jeffrey Snover

@DivineOps Every wave of automation Enables the next wave of automation

@DivineOps Infrastructure-level APIs

@DivineOps Borg cluster manager “Central to its success - and its conception - was the notion of turning cluster management into an entity for which API calls could be issued” - Google SRE book, 2017

@DivineOps Amazon Web Services: 2002 Amazon Cloud Computing: 2006 Azure Cloud Services: 2008

@DivineOps 2005 Infrastructure as code 2012 2009

@DivineOps We did NOT suddenly get the idea of infrastructure & platform automation 65

@DivineOps We did NOT suddenly get the idea of infrastructure & platform automation We gradually built the tools required to make it happen 66

@DivineOps Why does this matter?

@DivineOps If we get the origin story wrong, we end up working to solve the wrong problem!

@DivineOps Corollary 1: Hiring developers to do operations work ≠ effective SRE

@DivineOps We have seen success from hiring the skillsets across the entire landscape, hiring well-rounded folks with understanding of Ops and Dev concepts, as opposed to just Dev experience

@DivineOps Corollary 2: The desire to automate the infrastructure & platform operations is insufficient

@DivineOps Corollary 2: The desire to automate the infrastructure & platform operations is insufficient We need consistent APIs and reliable monitoring to unblock the automation

@DivineOps Early on, we had to move the Cloud Services Build system from on-prem to the Cloud, because it was not meeting our reliability and agility targets

@DivineOps What we all got wrong

@DivineOps Toil

Toil Toil is the kind of work that tends to be manual, repetitive, automatable, tactical, devoid of enduring value, and that scales linearly as a service grows. 76

@DivineOps SRE teams usually aim for under 50% toil

@DivineOps So, are we striving for a human-less system?

@DivineOps Second law of thermodynamics

@DivineOps With time, the net entropy (degree of disorder) of any isolated system will increase

@DivineOps

Entropy always wins
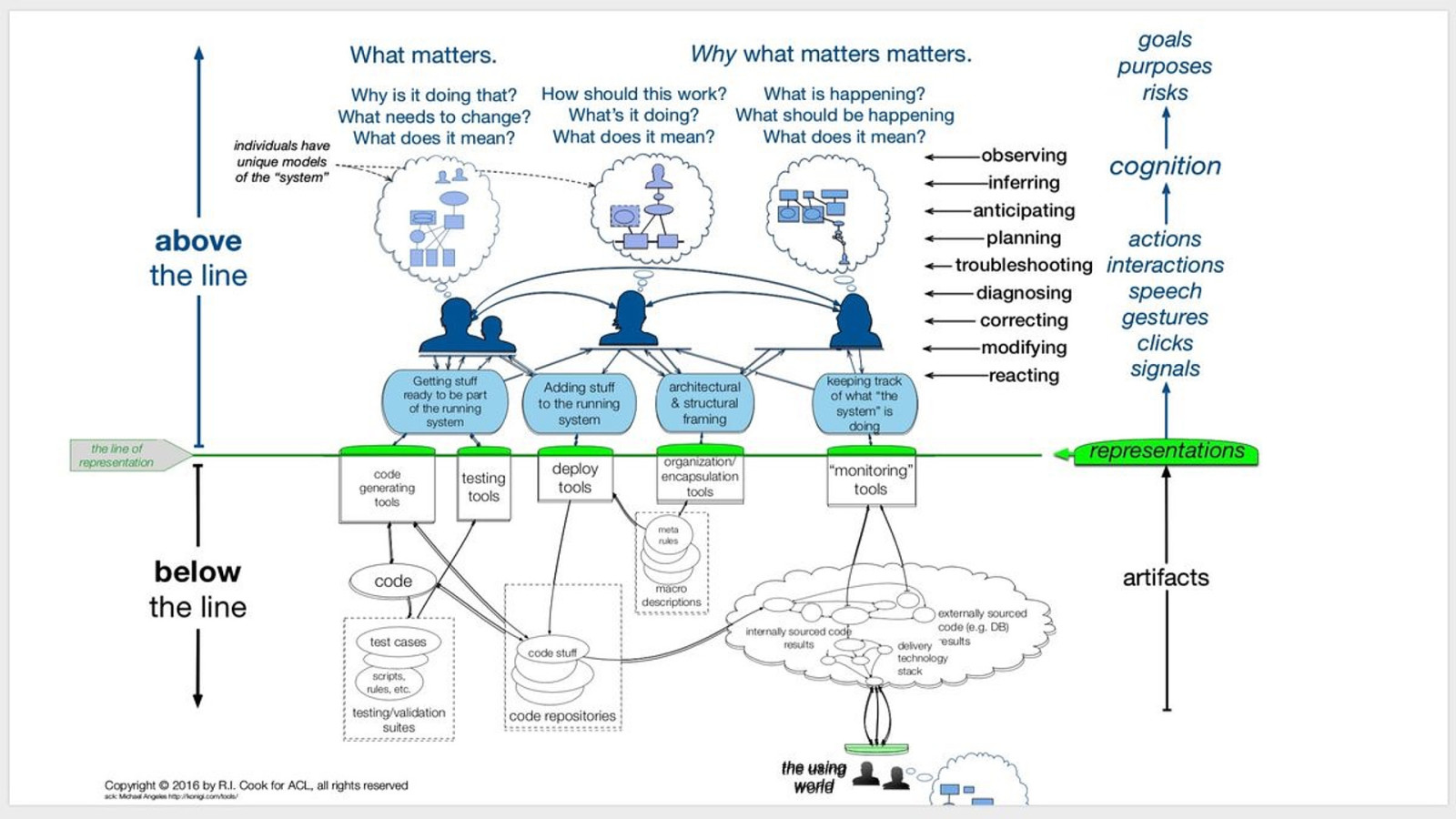

People working above the line of representation continuously build and refresh their models of what lies below the line. That activity is critical to the resilience of Internetfacing systems and the principal source of adaptive capacity. - Dr. Richard Cook
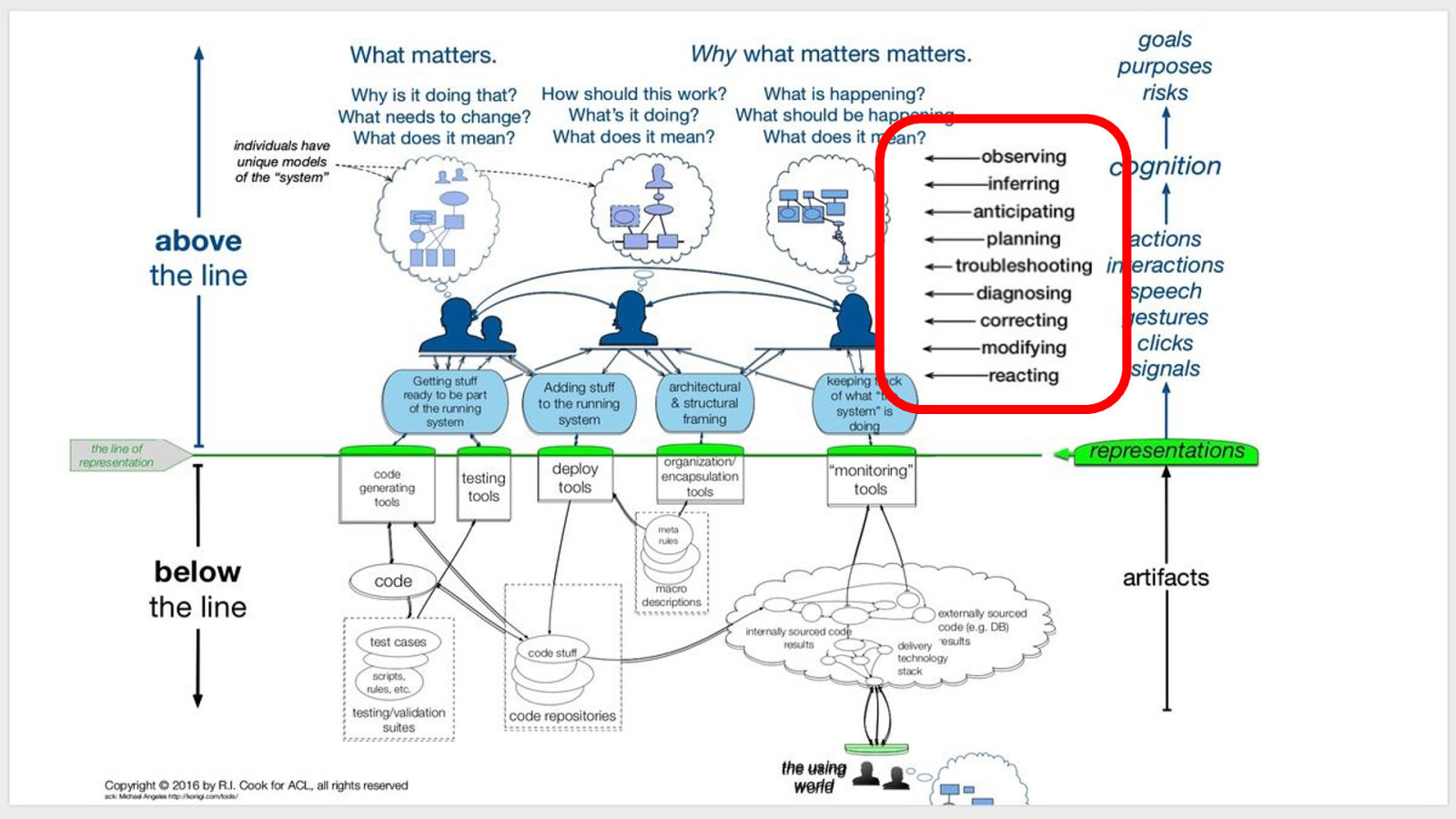

Resilience Velocity 2012: Richard Cook, “How Complex Systems Fail”

@DivineOps What we call toil is a major part of resilience and adaptive capacity

@DivineOps Perhaps we need a better way to look at toil

@DivineOps SRE folks worry that if they spend significant parts of their day focusing on toil, it will negatively affect their bonuses, chances of promotions etc.

@DivineOps If an employee is told that 50% of their work has no enduring value, how does this affect their productivity and job satisfaction? - Byron Miller

@DivineOps SRE Work Allocation

@DivineOps Work Allocations: SRE P and SRE O
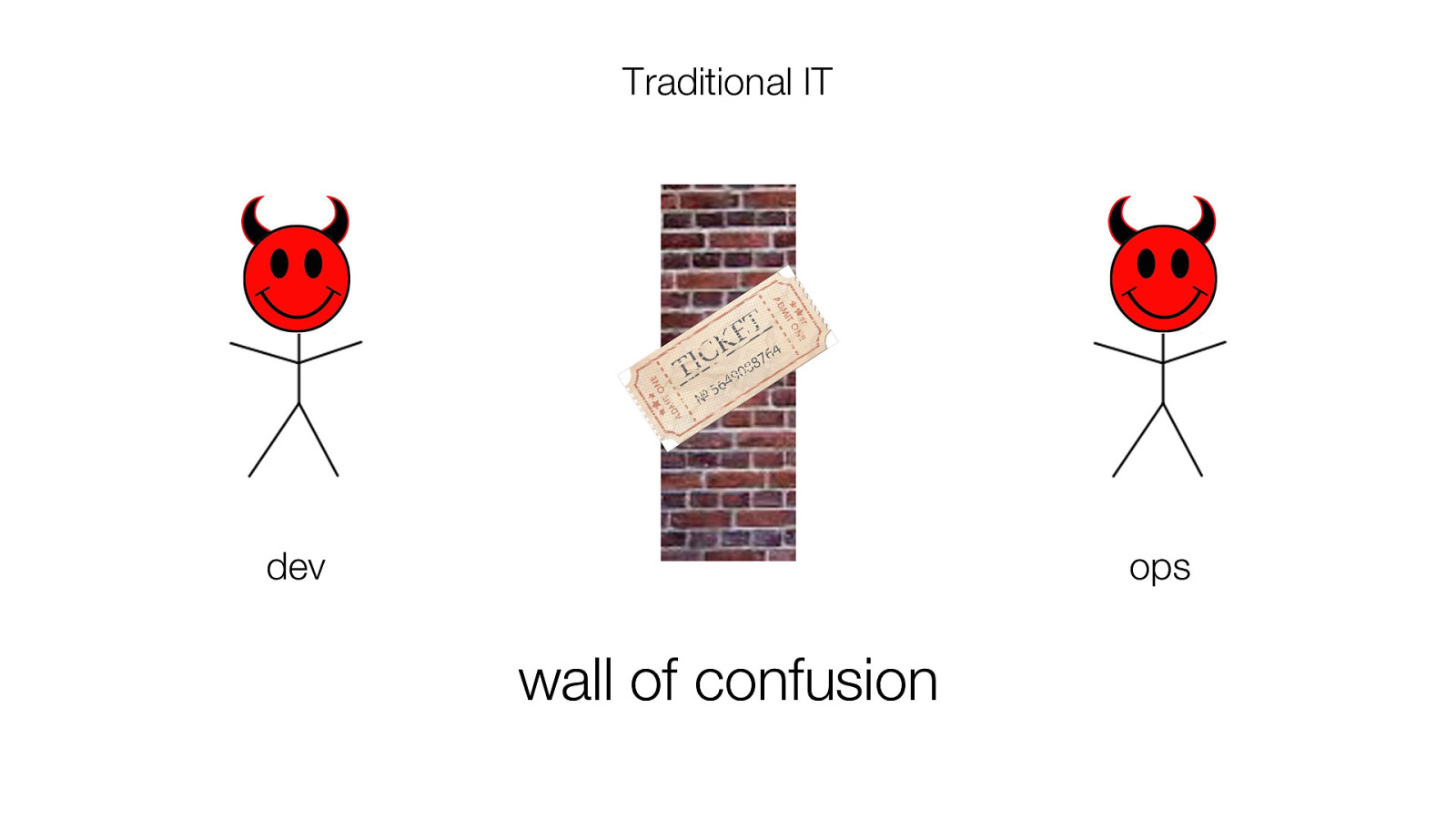
Traditional IT dev ops wall of confusion

@DivineOps Work Allocations: On-call once a month

@DivineOps SRE teams asked management for more on-call, as they were losing their “Ops muscle”

@DivineOps Work Allocations: Rotate engineers working on toilreduction tasks

@DivineOps Lack of continuity severely impacted team’s ability to deliver

@DivineOps Work Allocations: The search for the perfect system is still in progress!

@DivineOps Where do we go from here?

@DivineOps Let’s look at some of the insights from the talk:

@DivineOps Effective automation requires consistent APIs

@DivineOps Cloud

@DivineOps Cloud provides an industry standard for consistent infrastructure-level APIs

@DivineOps Are you in the datacenter management business?

@DivineOps Kubernetes
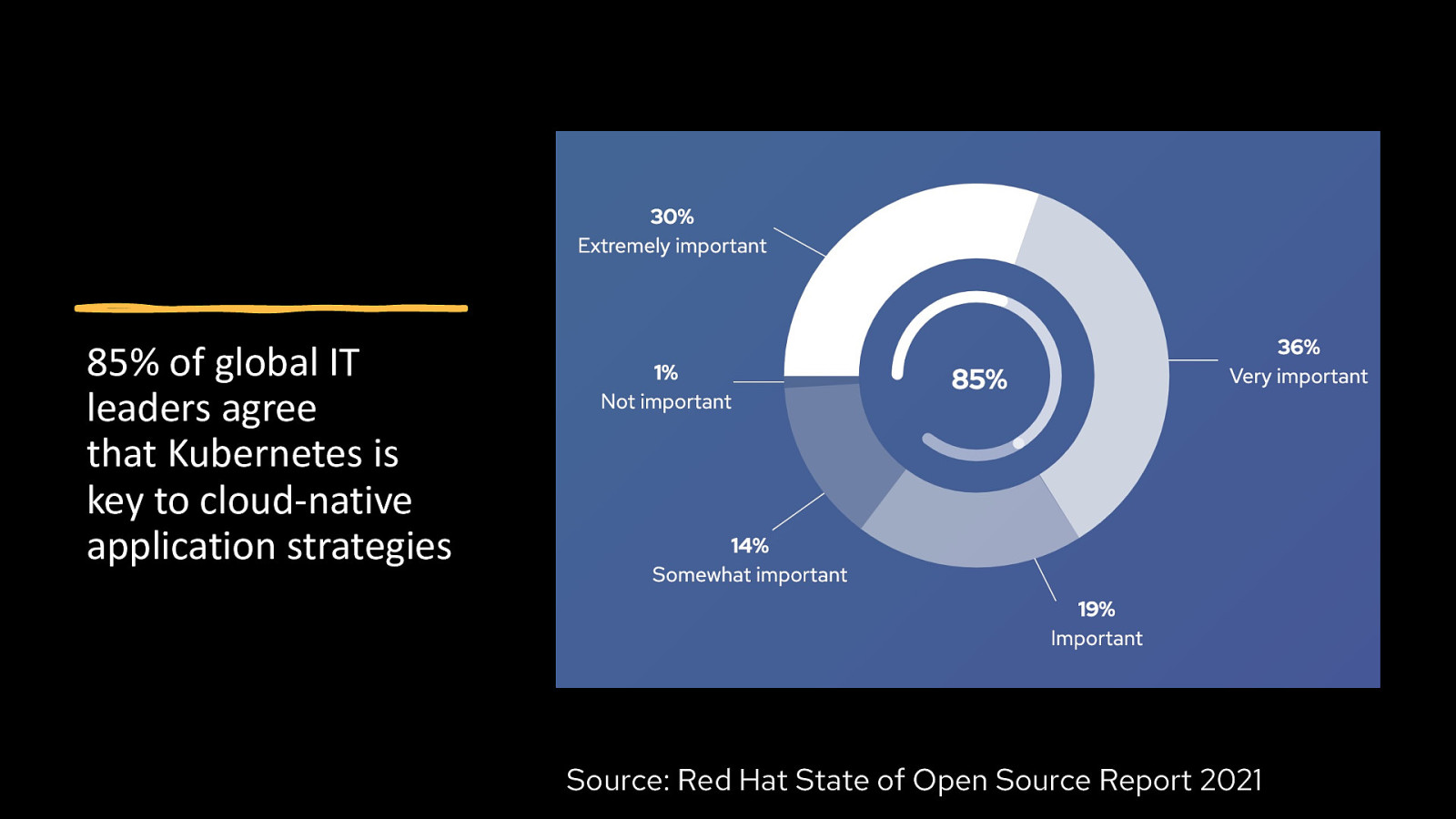
85% of global IT leaders agree that Kubernetes is key to cloud-native application strategies Source: Red Hat State of Open Source Report 2021 Source: Red Hat State of Open Source Report 2021

@DivineOps Kubernetes could provide the industry standard for consistent platform-level APIs

@DivineOps If building PaaS isn’t your company’s core business

@DivineOps If building PaaS isn’t your company’s core business Allow your provider to toil for you
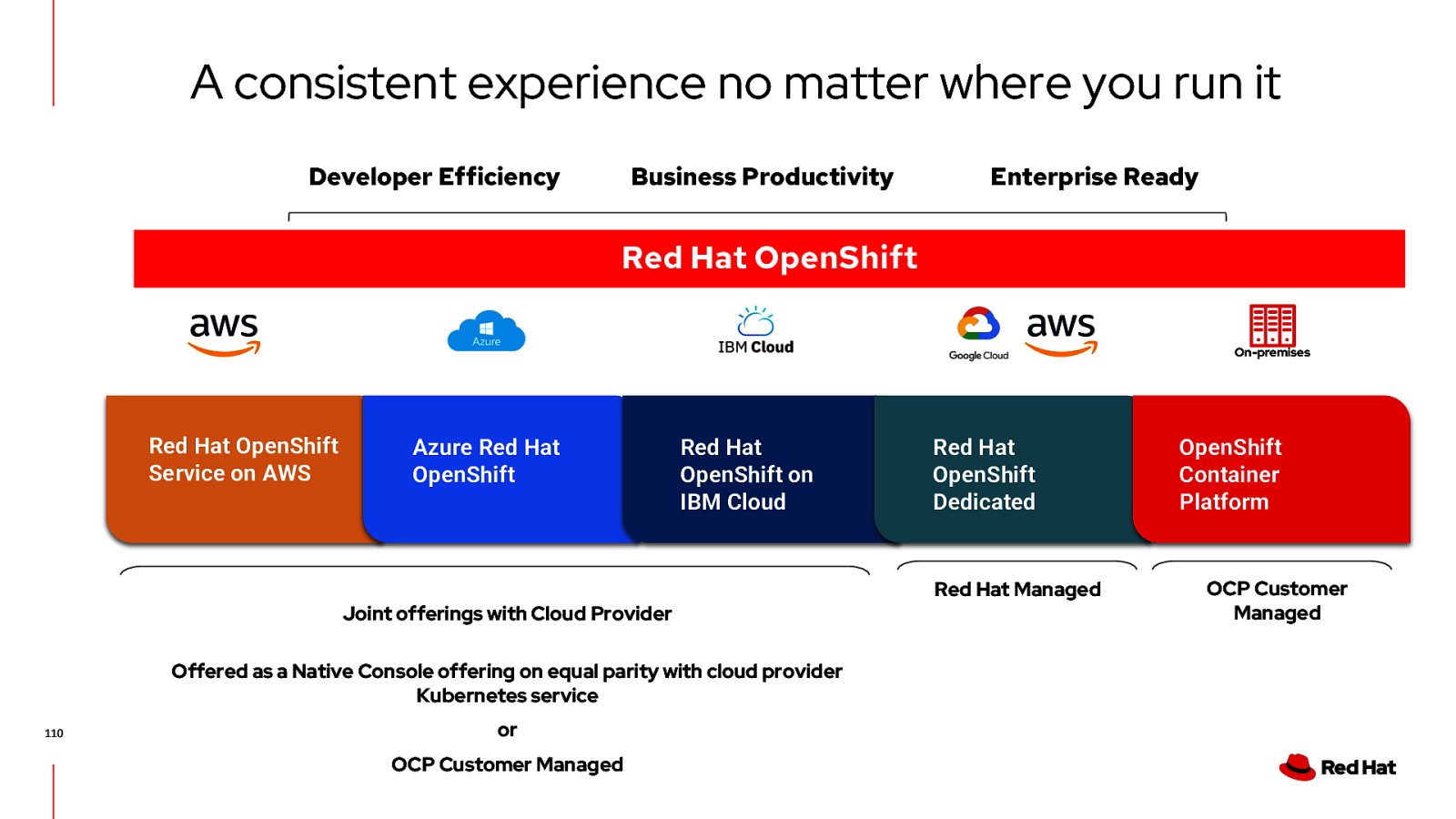
A consistent experience no matter where you run it Developer Efficiency Business Productivity Enterprise Ready Red Hat OpenShift On-premises Red Hat OpenShift Service on AWS Azure Red Hat OpenShift Red Hat OpenShift on IBM Cloud Joint offerings with Cloud Provider Offered as a Native Console offering on equal parity with cloud provider Kubernetes service 110 or OCP Customer Managed Red Hat OpenShift Dedicated Red Hat Managed OpenShift Container Platform OCP Customer Managed
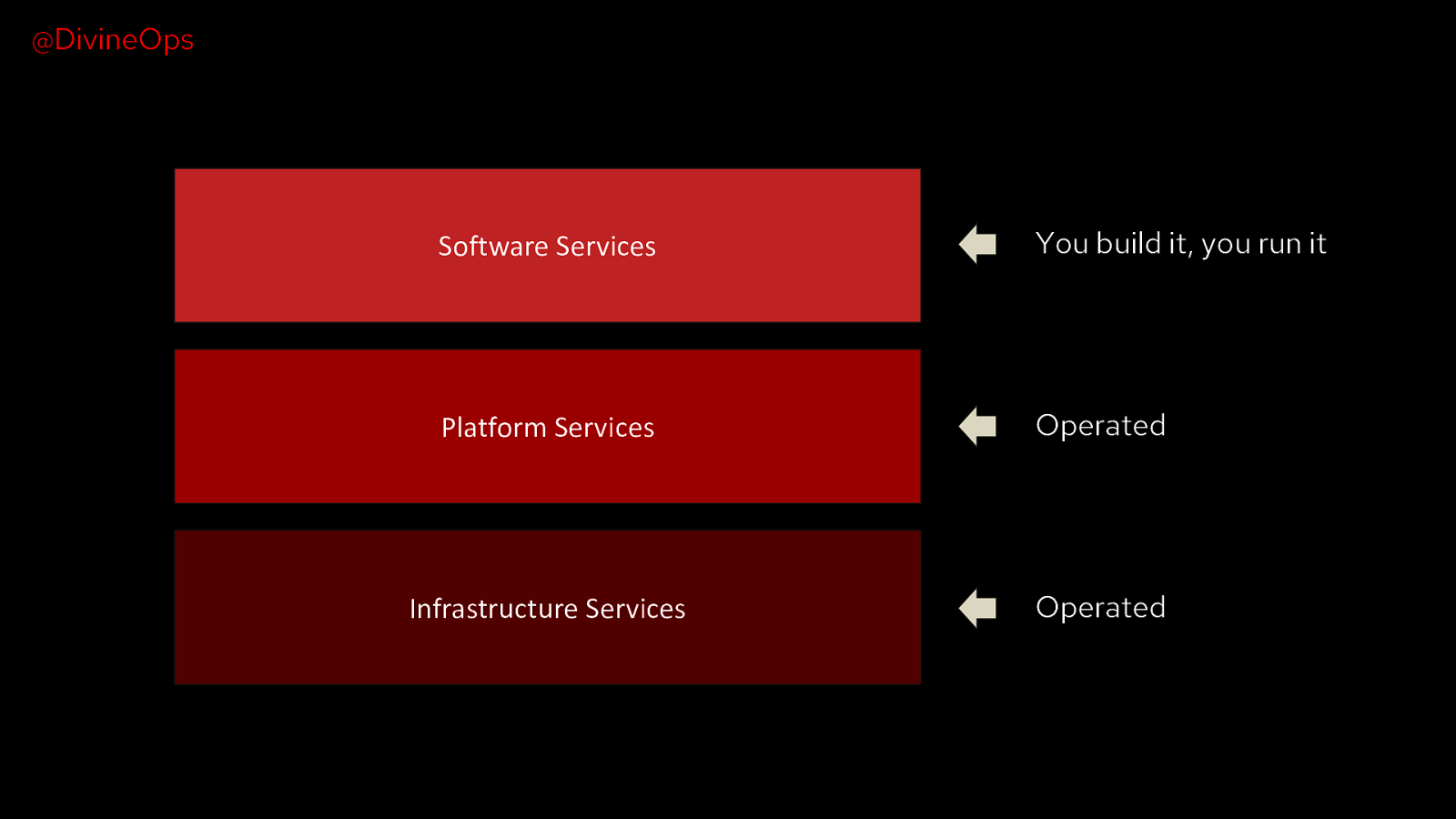
@DivineOps Software Services You build it, you run it Platform Services Operated Infrastructure Services Operated
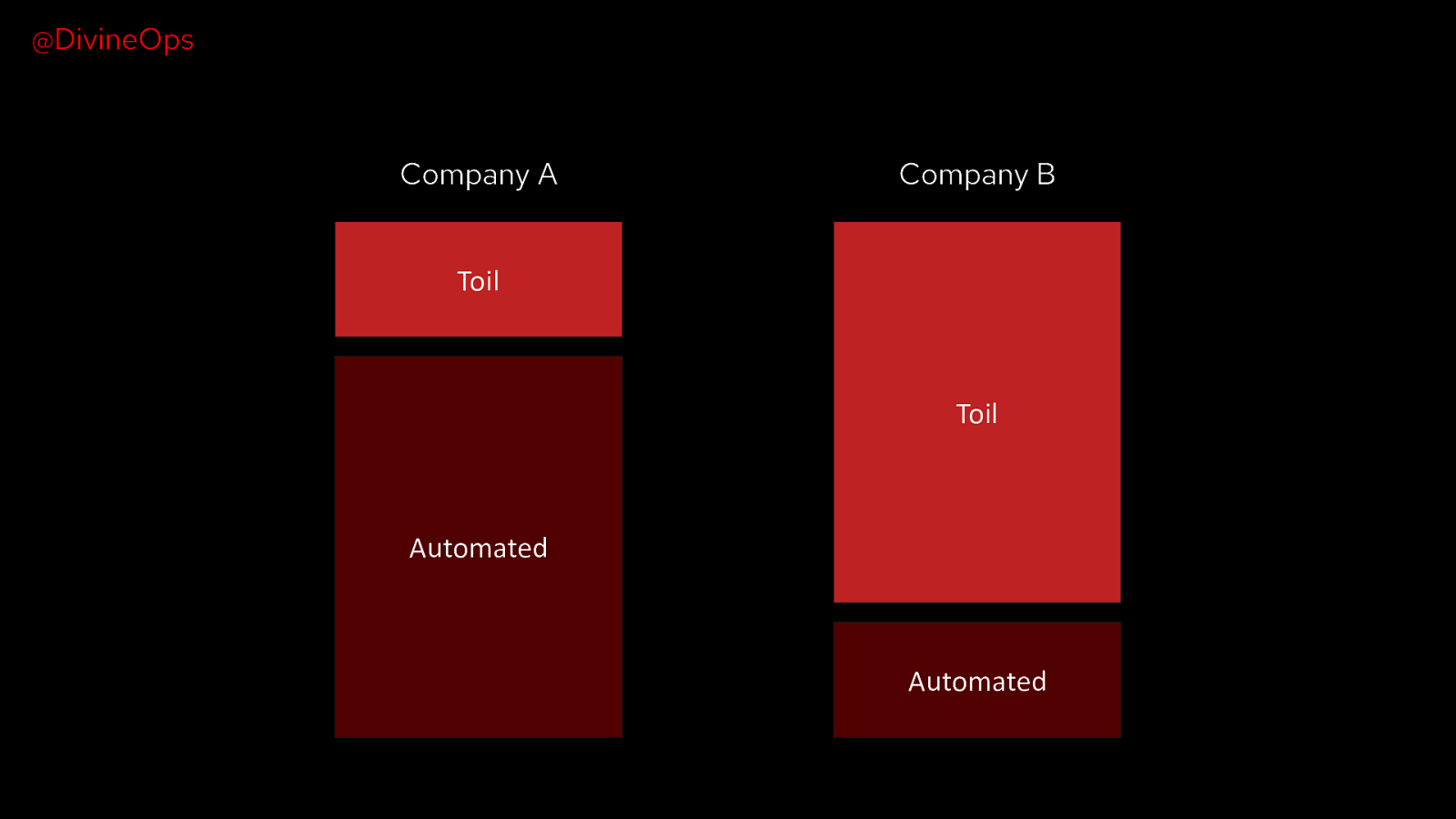
@DivineOps Company A Company B Toil Toil Automated Automated

@DivineOps Get your skills above the API! Image Source: Hans Moravec’s illustration of the rising tide of the AI capacity. From Max Tegmark (2017)

@DivineOps If building PaaS IS your company’s core business

@DivineOps Remember that SRE is about explicit agreements that align incentives

@DivineOps Focus your toil where your business value is

@DivineOps Last, but not least

@DivineOps Ideas are open source

@DivineOps Operate First A concept of incorporating operational experience into software development

@DivineOps https://operate-first.cloud/operations/sre

Thank you! @DivineOps Slides: speaking.sasharosenbaum.com

One of the most important decisions in building an SRE practice is what kind of work should be assigned to the SRE team, and in what percentages. At Red Hat, we ship OpenShift both as a product and as a service, which can make it extra difficult to draw the lines between feature development and toil automation work. In addition, we face the usual SRE struggle between striving for toil minimization and unintentionally devaluing Ops-type work.
In this talk, we will discuss the evolution from shipping products to running services, and what we’ve learned while trying different approaches.
 for free. You
can too.
for free. You
can too.